
An Empirical Investigation into the Limitations of Sparse Mixture of Experts for Small Scale Character Level Modeling
DOI:
https://doi.org/10.67119/1107ve04Keywords:
Character-level language modeling, ,Mixture-of-Experts, ,Sparse expert routing, Transformer, ,Small-scale modelsAbstract
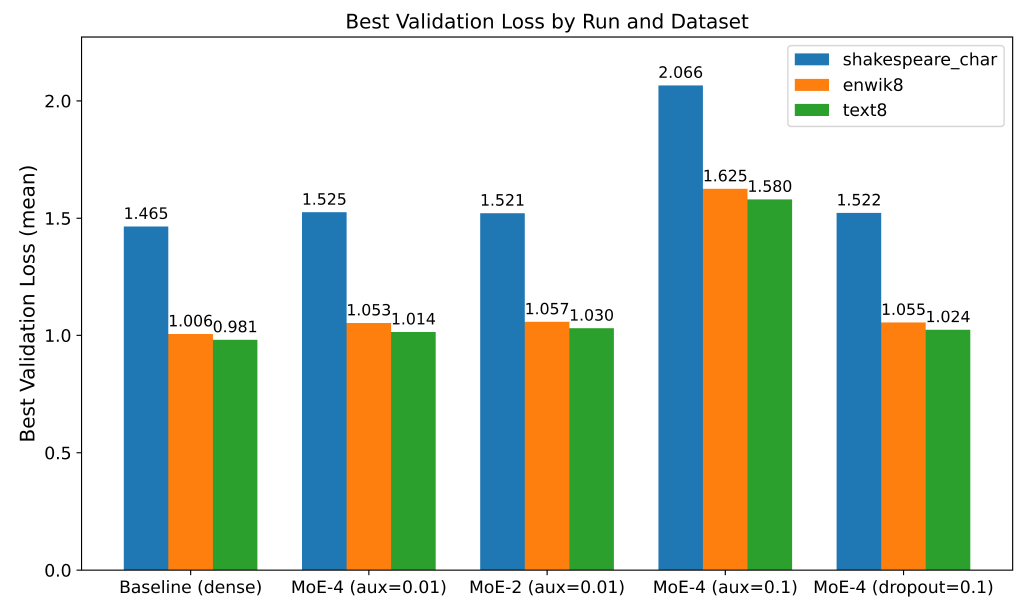
Mixture-of-Experts (MoE) models have demonstrated impressive scaling capabilities for large language models, yet their efficacy in small-scale, character-level language modeling remains unclear. We conduct a systematic study to evaluate whether sparse expert routing can improve generalization and efficiency under limited computational budgets. Adapting MoE to this setting is challenging due to auxiliary load-balancing losses that can destabilize training, increased parameter counts that may cause overfitting, and routing overhead that could negate theoretical gains. To address this, we implement a Switch-Transformer-style MoE layer with top-1 routing and an auxiliary load-balancing loss, comparing multiple MoE variants (varying the number of experts, auxiliary loss coefficient, and expert dropout) across three character-level datasets (shakespeare\_char, enwik8, text8). Our results show that all MoE configurations increase parameter count and training time, yet yield higher validation loss and slower inference speed compared to dense baselines. For instance, on shakespeare\_char the baseline achieves a best validation loss of 1.46 bits per character, while the 4-expert MoE reaches 1.53 bits per character. We also find that stronger auxiliary loss coefficients (e.g., 0.1 vs 0.01) destabilize training, and expert dropout fails to improve generalization. These findings indicate that the overhead of sparse routing outweighs its potential benefits in small-scale character-level modeling, providing valuable insights for future work on efficient expert utilization. The key contributions of this study include: (1) isolating the sparse routing effect in a character-level, low-resource regime; (2) providing a mechanistic explanation of routing failure via gradient conflict, expert specialization entropy, and computational overhead analysis; (3) establishing clear scale boundaries that delineate when MoE becomes detrimental versus beneficial.
Downloads
Downloads
Published
License
Copyright (c) 2026 International Journal of Artificial Intelligence and Green Manufacturing

This work is licensed under a Creative Commons Attribution 4.0 International License.


